Dalam proses penyimpanan data biasanya diperlukan optimasi besarnya file yang akan disimpan, mengingat kebanyakan user tidak selalu mempunyai ruang hardisk yang begitu besar. Kalaupun memiliki media penyimpanan yang cukup besar pastilah akan dioptimalkan penggunaannya. Salah satu caranya yaitu menggunakan kompresi data untuk menghemat ruang penyimpanan.Untuk proses kompresi dewasa ini(zip, rar,tar.gz) menggunakan gabungan beberapa algoritma kompresi dasar seperti LZW, SHANNON-FANO, HUFFMAN, gunzip, dan lain-lain. Pada coretan blog ini saya akan sedikit memaparkan tentang ALGORITMA SHANNON. Pada prinsipnya algoritma ini menggunakan pendekatan top down dalam penyusunan binary tree. Metode ini sangat efisien untuk mengompresi file text yang berukuran besar.
Untuk langkah-langkahnya sebagai berikut :
- Mengurutkan karakter berdasarkan probabilitasnya yang terbesar.
- Membagi menjadi 2 berdasarkan selisih paling sedikit dari nilai dua kelompok karakter yang terurut tadi.
- Secara rekursif dibagi menjadi 2 bagian, setiap bagian memiliki nilai yang sama atau dengan selisih paling sedikit.
- Mengasign nilai 1 kekanan dan 0 ke kiri pada pohon biner.
Source = {A, B, C, D, E }
Peluang={0.35, 0.17, 0.17, 0.16, 0.15
Membagi menjadi 2 kelompok besar:
- kelompok 1 = A dengan total peluang 0.35kelompok 2 = B, C, D, E dengan total peluang 0.65selisih kel 1 dan 2 = 0.30
- kelompok 1 = A, B dengan total peluang 0.52kelompok 2 = C, D, E dengan total peluang 0.48selisih kel 1 dan 2 = 0.04 --> paling sedikit
- kelompok 1 = A , B, C dengan total peluang 0.69kelompok 2 = D, E dengan total peluang 0.31selisih kel 1 dan 2 = 0.38
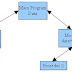
maka tree awalnya yaitu :

Kemudian dari 2 leaf yang terbentuk dilakukan proses pembagian lagi seperti diatas sampai tidak bisa dibagi lagi. Sehingga menghasilkan tree yang lengkap seperti berikut :

Setelah Tree lengkap telah terbentuk maka dilakukan pembacaan dari root sampai ke karakter pada leaf.
Dari pembacaan dihasilkan codeword sebagai berikut :
- A = 00 --> 2 bit
- B = 01
- C = 10
- D = 110 -->3bit
- E = 111
Lavg = 0.35*2 + 0.17*2 + 0.17*2 + 0.16*3 + 0.15 * 3 = 2,31 bit/char
Nilai entropinya yaitu
H( S ) = H( P1,P2,P3,P4,P5)
=-P1 log P1 -P2 log P2 - P3 log P3 - P4 log P4 - P5 log P5 --> log basis 2
= 2,23 bit/char
Jadi Efisiensinya = H(s)/Lavg = 2,232/2,31=96,67%
Jadi dengan metode ini akan terasa sangat efektif jika banyak terjadi perulangan karakter pada text. Dah capek ngetik nih....semoga bermanfaat...
References :
http://www.cs.cf.ac.uk/Dave/Multimedia/node209.html#SECTION04242000000000000000
Catatan kuliah q...



Tidak ada komentar:
Posting Komentar